Monolith to Microservices – A Journey
Monolith to Microservices – A Journey
Overview
Microservices is a buzzword today. Having experienced the drawbacks of monolithic applications, everyone looks forward to microservices for rescue.
Many times, as a quick solution, the big monolith is divided randomly into a set of small services. However, designing microservices is not just about limiting the size of the services. Using this approach, one can easily end up having a spaghetti of services – services with inter-dependency and tight coupling with other services. In such cases, change to one service leads to changes in many other services as well.
Objective
In this blog, we’ll see the evolution of architecture, of software systems, from the monolith to the Service Oriented Architecture, and to the Microservices Architecture. The reasons for this evolution from a design perspective, as well as from the deployment perspective will be elaborated as you read ahead.
By the end of this blog, you should get a fair idea of the principles of microservices, and should also be able to identify when to use and not to use microservices.
Example
Let’s take up an example that will show us the transformation of a monolith into SOA and then into microservices.
We will be taking an E-Commerce application as an example for this exercise. Since the application of e-commerce is well known, we will be able to concentrate more on the transformation process.
To simplify, let us consider three entities in the e-commerce application:
- Products
- Customers
- Orders.
The Monolith Version
A big monolith version of an E-Commerce looks like the following diagram –
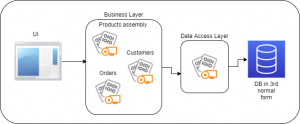
This is the simplest and quickest way to build an application. This design is used in many small applications, and it works! However, a few releases down the line, the drawbacks of this arrangement start showing up.
In an E-Commerce Application, for example, the Product Assembly has a lot of responsibilities, from product registration to maintaining the inventory and much more. Order Assembly handles orders in the process as well as the historical data and reports. Fixing an issue in the Products Assembly can break a report in the Orders Assembly.
There are also some real-life examples that many developers will be able to relate to their own experiences, like…
Any non-trivial change to a component causes a chain reaction, it causes changes in the rest of the components. Senior developers who know the code since inception become indispensable since they know the hidden dependencies very well.
Sometimes new screens or reports need the existing data in a different way which leads to the addition of redundant data because changing the existing schema is a dreaded task. A lot of code can break and can require extensive fixing and testing.
Let’s look at the deployment diagram for some more drawbacks related to scalability.
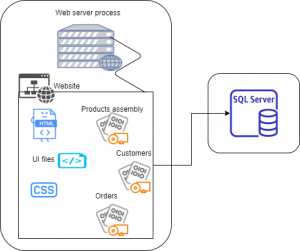
As shown in the diagram above, a website consists of UI files – HTML, script, CSS files, and Assemblies with business logic. This makes the website a big monolith with a slow-moving set of components.
The components are tightly coupled. Most of the components need to live together on a single server, the only exception is the DB which can live on its own server.
‘Scalability’ needs to be applied to the application as a whole, and many times, scalability simply implies upgrading the underlying hardware. There is hardly any way to scale up only a part of the application. Let’s say the feature “product search” needs to be given more processing power, it is difficult to scale up without making significant code changes.
If this application needs to be hosted on the cloud, the options are IaaS VM ( Infrastructure as a Service Virtual Machine), cloud service on Azure, or an EC2 instance on AWS. IaaS components are less optimized in terms of resources than the PaaS or SaaS components since IaaS requires dedicated resources whereas PaaS and SaaS use shared resources.
This design is only marginally better than the 2-layer architecture aka UI-firing-DB-queries design. (In case you are interested in this architecture, please refer to https://www.guru99.com/dbms-architecture.html#3)
The SOA Version
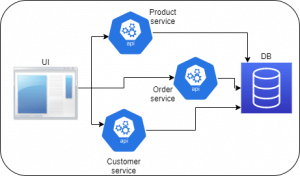
The design shown in the above diagram or its variant is used in order to work around the drawbacks of the tightly coupled monolith design. It’s called SOA – Service Oriented Architecture.
Here in SOA, we have REST API services – Product service, Order service, and Customer service instead of the Assemblies. Each service is an independent component that can run on its own. It can be developed and tested independently. It exposes a well-defined interface to its users.
The UI in an SOA is lightweight with only views and rendering logic and a few validations. The UI calls the services using REST.
If the services in an SOA need to communicate with each other, they use REST API calls or other means like an Enterprise Service Bus. The principle is to use advertised public interfaces for communication, and not depend on the internals of the implementation of any service.
Despite all the above advantages, there is one small pitfall – the database is common! SOA principles ask for services with explicit boundaries, but there is no explicit restriction on data sharing. This often leads to various services sharing a database.
It can lead to issues like
- Concurrent, asynchronous updates by different services
- Race for connections
- DB schema change impacts all services
- Whole DB needs to scale up – we can’t scale up only product data in order to speed up the product searches.
Apart from the shared DB, the SOA doesn’t limit the size of a service. This often leads to services turning into miniature monoliths
The following deployment diagram gives a picture of how the services and UI are laid out when running in production.
Services can co-exist on a single server or can be spread across servers, depending on the traffic. Since each service is an independent unit of implementation and deployment, it can follow its own release cycle. Each service can be scaled up or down depending on the traffic visiting the service.
When the application needs to be deployed to the cloud-
- The UI can be deployed as an app service or blob storage on Azure / S3 on AWS.
- The web services can be deployed to app services on Azure or EC2 instances on AWS.
- The database can be hosted on SQL Azure or RDS on AWS.
Most of these components are PaaS, since PaaS is more optimized for resources it is preferred.
As described above, a service can be a miniature monolith. It takes up too many responsibilities resulting in performance issues. Fixing performance issues of a monolith service requires re-design or split of the service into two or more services.
But instead of redesigning it, often a quick solution is to give more resources to the service which means the real problem remains untouched while a superficial solution is applied.
The Microservices Version
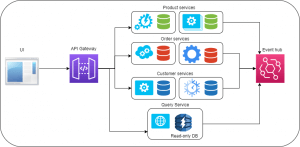
The diagram given above depicts Microservices architecture.
Here, we see multiple services – Product, Customer, and Order services. Each service has its own database. The size of each service is such that it serves one small purpose in a cohesive way.
The UI is interacting with the services using an API gateway, which is another service responsible for connecting other services to the UI.
The services are communicating with each other using the Event Hub. There is a new service called Query service – this helps with querying the data from a read-only database. The read-only database integrates all the small service-specific databases so that the dashboards and the reports find it easy to query a single, integral database.
Let’s delve into the guiding principles behind the microservices solution.
- Independent small size services
Product service may be divided further into smaller services – one for basic product CRUD operations, and the other for product inventory. Similar logical division can be done for each of the main services, here, customer service and order service.
- Database-per-service
This principle avoids the contention for database resources by multiple services. Each service owns, maintains its own small-scale database.
- Data sharing among services
With an independent database we arrive at a question – how do the services share the required data?
The solution is a common message/event store. Each service publishes events when data changes and other services subscribe to the events of interest.
Let’s see how this helps with a few examples
-
- The ordered service needs product details and customer details. How does it get it? The solution is to replicate the required data fields only in its own database – the order service can store product ids and customer ids. When a new product is added to the product service, it publishes an event with its id to the event store. The ordered service subscribes to it and adds the new product id to its database.
- The product service is responsible for maintaining product quantities. But quantity needs to be reduced when an order is placed – which is done by the order service. In this case, the order service publishes an event with the product id and the quantity as the event data. The product service subscribes to it and updates the quantity in its database.
- A holistic view of data
There is another problem with this design – how do we build a dashboard for a quick view of the current status of products, orders? It needs data from so many microservices. Is it going to be a tough task with the micro-services architecture?
Fortunately, no – it’s not a tough task. The solution is to create a read-only database which is kind of old-style – the whole database in a single place! A query service will have APIs to retrieve data exactly as required by the dashboards. This database can be updated on a schedule, with frequency as much as a few seconds, or it can also be updated based on the events.
This pattern is known as CQRS – Command Query Responsibility Segregation
- Integration with UI
Yet another problem the UI developers will face – how many microservices will they need to integrate into their code? The answer is, just one or two! Thanks to the ‘API gateway’ service, which acts as a bridge between the set of microservices and the UI!! The UI just needs to call the API gateway service and the Query service. This is perhaps simpler than the older business layers integration!!
The following diagram illustrates a sample deployment of a microservices solution.
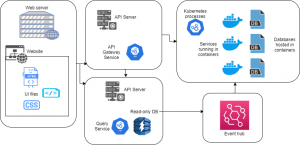
As depicted in the above diagram, the services are loosely coupled, often containerized.
The responsibility of maintaining the container instances is automated with a Kubernetes service so that if any container goes down a new instance is created automatically. Often, the Kubernetes cluster contains more than one node, and when one node goes down, the other one is already ready to take over.
The services with more traffic are scaled up with more container instances, all without any human intervention.
The API Gateway service and the Query service can be microservices hosted in containers, or they can be simple, SOA style, RESTful services which can be deployed to API servers. The deployment diagram above shows the second approach, to emphasize the fact that microservices and older RESTful services can be combined together in an application. This fact also helps in the phase-wise transition of older services to microservices. A few performance-critical services can be transitioned into microservices first while the rest of the services remain the old SOA style.
The microservices solution is often deployed to the cloud although deploying on physical servers is also possible. The cloud provides the following options
- Container registry on Azure and AWS for running containerized microservices and the database
- EventHub on Azure, EventBridge on AWS. Both are PaaS
- App Service on Azure, EC2 instance on AWS for hosting RESTful services
- Blob storage or App Service on Azure, S3 on AWS for hosting the website
When Not to Use Microservices
So far, it looks like microservices are a silver bullet, can cure any scalability and maintainability issues in software products! Yes, well, almost all issues (but not ALL!).
So what are the cases when microservices may not be a right solution? Let’s see –
- ACID transactions spanning services are must
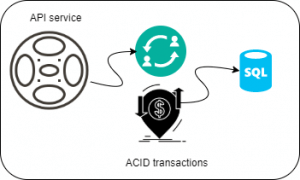
Microservices guarantee eventual consistency of data, however, they do not guarantee ACID transactions across services. In fact, if you can design such a solution using microservices, look for violations of microservices principles in your design!
In case of such a requirement, you can try to contain the whole logic which is needed for the transaction in a single microservice. This will help you reap the benefits of microservices while still fulfilling the business requirement of ACID transactions.
- The deployment process is manual

The deployment automation must be planned along with microservices transition. Manual deployments for a microservices solution is a strict no-no! The dev ops, or developers deploying the number of services manually would just start dreading the task!
- Scaling decisions are manual

The scaling of services is a manual decision in your organization – Scaling microservices up and down must be an automatic process based on criteria like memory or CPU usage.
- Physical infrastructure is used
Microservices are more suitable for the cloud environment where infrastructure is virtual since the cloud providers have services which support scaling up and down based on rules.
Conclusion
We have seen the journey of software application architecture from Monolith to SOA to Microservices. To conclude, microservices are a boon, if understood in the true spirit.
It’s a transformation which involves not only architecture and design changes, but also deployment and maintenance process changes. It asks us to embrace automated deployment, monitoring and scaling along with the design changes to split services into small manageable units.
It is not a quick fix solution to any scalability or performance issue. It’s a change of mindset where we think of the whole picture starting from the design to the deployment and maintenance.
Microservices also make the transition to cloud easier and more optimal. Containerization and deployment automation go hand in hand with microservices.
Thanks for being part of this article’s journey so far! Feel free to like, clap and share!! Happy computing!!!
Written By:
Sameeksha Chepe