Conversational AI: Inside Rasa’s open-source approach
As the post-pandemic world is pushed more towards engaging customers online, leveraging chatbots and messengers has become a priority for organizations. But a chatbot with few static lines of fixed responses is not sufficient to handle the dynamics of customer conversations.
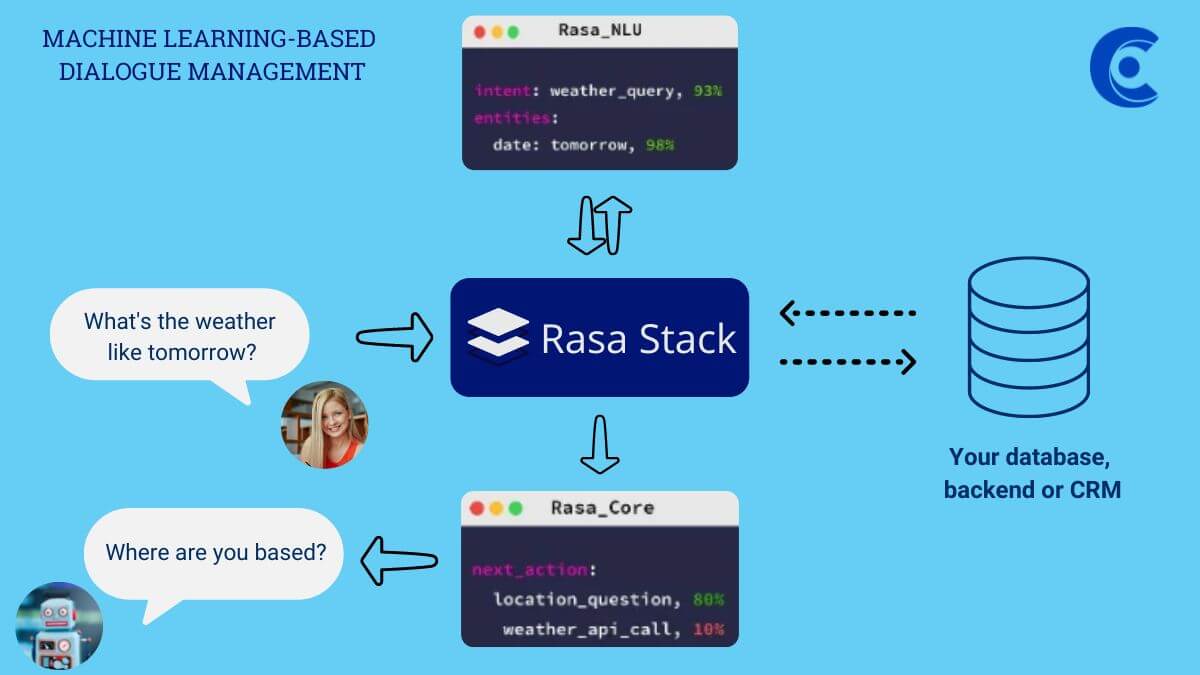
If you want to create a successful automated chat program using Rasa, you need to understand how it functions. Rasa uses intent and entity recognition to decipher the meaning of text messages and determine the appropriate response. By understanding how Rasa works, you can create a chatbot that effectively meets your needs. Now let’s see how this all works.
Rasa has these two main components configured in the config.yml file. This config.yml file declares all the settings for the machine learning pipelines that Rasa is using under the hood.
Rasa NLU (Natural Language Understanding): The NLU pipeline defines the processing steps that convert unstructured user messages into intents and entities.
Components of Rasa NLU:
Tokenizers: The first step is to split an utterance into smaller chunks of text, known as tokens.
Featurizers: Featurizers generate numeric features for machine learning models.
Intent Classifiers: Features can now be passed to the intent classification model. Rasa’s DIET (Dual Intent and Entity Transformer) model can handle both intent classification as well as entity extraction.
Entity Extractors: Incoming text is converted to tokens using Tokenizers, POS tagger attaches to part of speech tag to each word, Chunker groups into ‘noun phrases’, and then the entity is recognized and extracted.
Even though DIET is capable of learning how to detect entities, it’s not recommended to use it for every type of entity out there. For example, entities that follow a structured pattern, like phone numbers can be handled with a RegexEntityExtractor instead. This is why it’s common to have more than one type of entity extractor in the pipeline.
Rasa Core: With the NLU pipeline, we detect intents and entities. But this pipeline doesn’t predict the next action (handle the sequence of dialogues) in the conversation. That’s what the policy pipeline is for. Policies make use of the NLU predictions as well as the state of the conversation so far to predict what action to take next.
Three different policies that the default config.yml file starts out with:
RulePolicy: Handles conversations that match predefined rule patterns.
MemoizationPolicy: Checks if the current conversation matches any of the stories in your training data.
TEDPolicy (Transformer Embedding Dialogue Policy): Uses machine learning to predict the next best action.
These policies operate in a priority-based hierarchy. With standard settings considerations, the RulePolicy > MemoizationPolicy > TEDPolicy.
How did you approach your Conversational AI use case?