How to do Data Extraction from PDFs – for First Timers
How to do Data Extraction from PDFs – for First-Timers
Data Extraction from PDFs can feel like a locked vault sometimes. You might end up googling multiple times and still end up nowhere.
Don’t worry, we have been there and done that. That’s why in this Blog we share our learning to save you a ton of time!
Our Approach
When PDF Data Extraction is needed our natural tendency is to do that manually.
We can simply copy the data and paste it into a Word document but when you are working with a lot of data, manual data entry is tedious, error-prone, and time-consuming.
You could also try doing that via online data extraction tools, but that compromises your security and it’s not ideal for a large number of PDFs.
We present you with a different approach which is based on our experience of Data Extraction from PDFs.
The motive behind this data extraction was to have data that could be queried, filtered, and used for analytics. To do so, the data needed to be at some central place like a Database instead of it being distributed in different PDFs.
Data Categorization
We started with understanding the PDF provided to us. After going through a detailed study we categorized the contents in the document into three parts.
1) Regular Text
2) Data in tabular format
3) Images containing Tables
Identifying Data Extraction Methods
We found ways to scrape data from PDFs using various APIs, frameworks, paid libraries, and other tools.
Finding the right technology among them was a great challenge. We tried around 10 to 20 different technologies/ libraries with different programming languages to compare accuracy in the output.
After our analysis, we concluded that there is no single library that could parse text, tables, and images. So we used a fusion of various techniques/ APIs as per our requirements and developed a utility that could parse our document.
Extracting – Regular Data
Our journey started with extracting textual data- text with numbering & text with bullet points present between the header and footer.
Challenge was not text extraction, but the visual elements like the bullet points. It was not possible to extract the position of text with these visual elements. To overcome this challenge, we applied regex-based intelligence to identify this type of separator to achieve maximum accuracy.
PDF is not only structured plain text. Text can be present at different places in different formats like- tables with space boundaries, tables with rigid boundaries, nested tables, headers, footers, TOC, Page numbers, etc.
When you try extracting text in tabular form using text extraction libraries, it will be successful but one will not be able to identify the column header, data, title, etc. Extraction of tabular data needs a different approach.
Extracting – Tabular Data
If you have a PDF with many pages and you don’t know where the tables are then there can be two approaches:
- In the first approach, you will need a Table Detection Algorithm that will identify the tables in the PDF, and then you can use any tabular data scraping library for parsing the identified tables. Writing a table detection algorithm is a costly affair and it may not give you 100 percent accuracy in all cases.
- In the second approach, even without writing a Table Detection Algorithm, you can directly pass the entire file into table parsing libraries as they internally identify the tables and perform parsing on them. ( Better approach )
Your document could either have only tables or it could have an index that states where the tables are present. If you know where the tables exist in your document, then you can directly parse the identified pages using tabular data scraping libraries.
Different Kind of Tables found in PDFs-
1) Space-separated tables [Stream Tables]
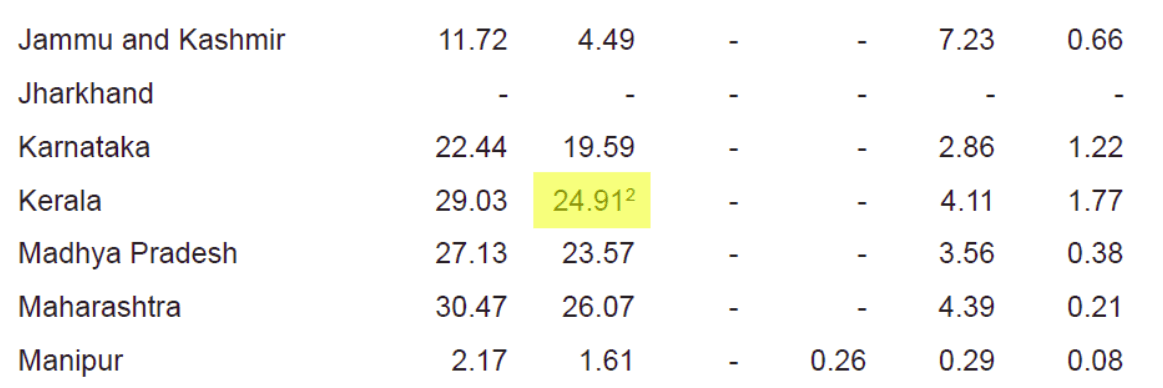
2) Line separated tables [Lattice Tables]
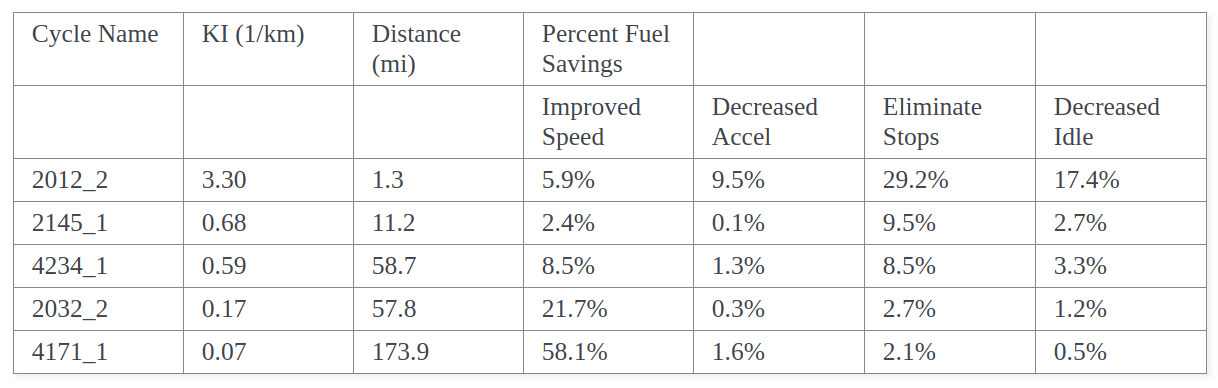
3) Extracting tables from Images [Scanned Images]

Note: Blurred image hence hard to identify diff between dot [.] & comma [,]
Extracting – Data from Images
PDFs may also contain scanned images. Images may contain plain text or tables. Scraping text can be easily done using any OCR library, except for some bad-quality images.
For example, in a bad-quality image, it is hard for OCR to differentiate between a dot[.] and a comma [,] (as shown in the 3rd image below). These kinds of issues limit the accuracy of OCR and need manual intervention.
If you have similar requirements, please don’t hesitate to reach out to us!
We hope we were able to give you enough information to get you started with Data Extraction from PDF files.
Thanks,
Rishikesh Chaudhari & Harikrishnan Pillai
Comment (1)
[…] these factors and taking the right steps, we have successfully delivered Data Science projects, from concept to execution to […]
Comments are closed.